16 進数表示するコマンド (2) hexdump
ヘックスダンプをするためのコマンドとして、xxd コマンド の他に、 その名の通り hexdump コマンドも使えます。
xxd コマンドについては「16 進数表示するコマンド (1) xxd」をみてください。
hexdump コマンドも xxd コマンドと同様に、 ヘックスダンプするファイル名を受けとります。また、標準入力からも入力を受けとります。
オプションなしで hexdump コマンドを実行すると、次のように表示されます。
$ hexdump a.txt
0000000 4241 4443 4645 4847 4a49 4c4b 4e4d 504f
0000010 5251 5453 5655 5857 5a59 000a
000001b # 末尾のオフセット
出力はxxd コマンドとほぼ同様なのですが、大きな違いが二つあります。
ひとつ目の違いは実行環境のエンディアンで表示します。この例では 2 バイトまとまりで、リトルエンディアンで表示されています。
もうひとつは最後に末尾のオフセットが表示される点です。
フォーマット例
hexdump コマンドで特徴的なのは、ユーザー定義のフォーマットができることです。 ここではフォーマットを行う例を少し紹介します。
hexdump コマンドでは -e オプションでフォーマット文字列を指定します。
フォーマット文字列を複数並べることができます。
完全に説明するのはなかなか厄介なので、いくつかの具体例を挙げながら説明します。
4 バイト毎にオフセットとヘックスダンプと文字を表示
4 バイト毎に「オフセット」と「ヘックスダンプ」と「対応する ASCII 文字」を表示するコマンドは次のようになります。
$ hexdump -e '1/4 "%07_ax %08X "' -e '4/1 "%_p"' -e '"\n"' a.txt 0000000 44434241 ABCD 0000004 48474645 EFGH 0000008 4C4B4A49 IJKL 000000c 504F4E4D MNOP 0000010 54535251 QRST 0000014 58575655 UVWX 0000018 000A5A59 YZ.
フォーマット文字列は3個指定しています。パッとみて、何をしているか分かりにくいと思うので、ひとつひとつ説明します。
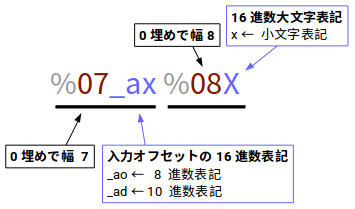
-e '1/4 "%07_ax %08X "'
-e に続けて、シングルクォートでフォーマット文字列を指定しています。
フォーマット文字列の内容は 1/4 "%07_ax %08X " です。
1/4 の部分は 「4 バイト毎に 1 回フォーマットを実行する」ということを表しています。 スラッシュ / の直後の数字 (ここでは 4) は「バイトカウント」と呼びます。
C 言語のフォーマットのように、% 記号に続けて、「幅」(と、幅に満たないときに埋める文字) と 「変換文字」 を指定します。
変換文字は多数ありますが、主なものを表にまとめます。
| 変換文字 | 利用可能な バイトカウント |
変換内容 |
|---|---|---|
| %_a[dox] | (任意) | 開始オフセットバイト数 %_ad = 10 進数表記 %_ao = 8 進数表記 %_ax = 16 進数表記 |
| %_p | 1 | ASCII 文字。非表示文字は . に変換。 |
| %_u | 1 | ASCII 文字。制御文字の意味表記有 |
| %d | 1, 2, 4 | 10 進数 |
| %o | 1, 2, 4 | 8 進数 |
| %X | 1, 2, 4 | 16 進数大文字 |
| %x | 1, 2, 4 | 16 進数小文字 |
| %E | 4, 8, 12 | 数値 (科学的表記) |
| %f | 4, 8, 12 | 浮動小数点 |
気を付けないといけないのは、基本的に変換文字毎にサポートされるバイトカウントが決まっているということです。 例外として %_a は任意のバイトカウントで実行できます。
例えば、上表で %_u のバイトカウントは1 であると記載されていますが、 このときに、バイトカウントを 2 としてフォーマットを実行すると、「間違ったバイトカウントです」という意味のエラーが表示されます。
バイトカウントについては、複数のフォーマット文字列を指定したときに、より注意が必要になってくるので後でもう少し説明しますので、読み進めてください。
以上で、最初のフォーマット文字列 1/4 "%07_ax %08X " は 「4 バイトのバイトカウントで 1 回、フォーマットを実行。 そのときには 16 進数表記のオフセットバイトを 7 文字幅で 0 埋めで表示。スペースを表示したあと、 バイトカウントの 4 バイト分のバイト列を大文字 16 進数で 8 文字幅 0 埋めで表示する」というフォーマットを行ったことがわかりました。
続けて、次のフォーマット文字を見てみましょう。
-e '4/1 "%_p"'
-e に続けて、シングルクォートでフォーマット文字列を指定しています。
フォーマット文字列の内容は 4/1 "%_p" です。
4/1 の部分は 「バイトカウント 1 で 4 回フォーマットを実行する」ということを表しています。1 バイト毎にデータを取り出して、 指定したフォーマットで 4 回フォーマットを実施するということです。
フォーマットは変換文字のみを指定しています。 %_p です。
%_pは、上表にも記載している通り、「バイトを ASCII 文字で表記し、非表示文字についてはドット . で表す」 というものです。
また、このコンテキストではバイトカウント 1 としていましたが、%_p は確かにバイトカウント 1 で実行できることにも注意してください。
続けて、最後のフォーマット文字列も見てしまいましょう。
-e '"\n"'
フォーマット文字列の内容は "\n" だけです。
フォーマット文字では通常の文字も表示できますし、このようにエスケープシーケンス付きの制御文字も使えます。主なエスケープシーケンスを表に記載します。
| 意味 | エスケープシーケンス |
|---|---|
| 改行 (ラインフィード) | \n |
| キャリッジリターン | \r |
| タブ | \t |
以上で、フォーマット文字列を全て説明しました。
もう少しだけ、バイトカウントとフォーマット回数について補足しておきます。
バイトカウントと繰り返し単位
上の例ではひとつめのフォーマットがバイトカウント 4 で 1 回のフォーマット。二つ目のフォーマットはバイトカウント 1 で 4 回のフォーマットを実施しています。
図にすると下のようになります。
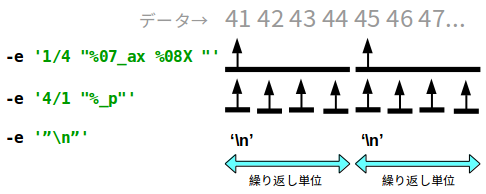
繰り返し単位となるバイト数は、全てのフォーマット文字列で必要とするバイト数の最大値と等しくなります。
ここでは 「4 バイトカウント × 1 = 4 バイトのフォーマット」と「1 バイトカウント × 4 = 4 バイトのフォーマット」 を実施しているので、繰り返し単位のバイト数は 4 バイトとなります。
フォーマットのバイトカウントと繰り返しによっては、一部のデータが表示されないなどの問題が起きる可能性があるので、注意が必要です。
例えば、二つ目の文字列フォーマットの繰り返しとバイトカウントを 2/1 とすると、 次のように ASCII 文字は繰り替えし単位ないの先頭の 2 バイト分しか表示されないことになります。
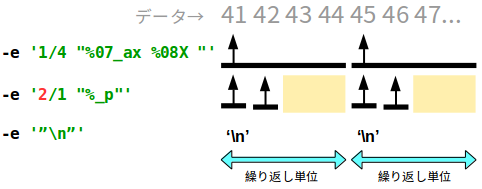
実際に実行すると、次のように 1 行目に "AB" が出力されて、2 行目は "EF" となり、"CD" の部分がスキップされていることがわかります。
$ hexdump -e '1/4 "%07_ax %08X "' -e '2/1 "%_p"' -e '"\n"' a.txt 0000000 44434241 AB 0000004 48474645 EF ...
繰り返しとバイトカウントの省略
繰り返し回数やバイトカウントは既定で 1 です。その場合は次のように省略することも可能です。
バイトカウント 1 で 16 回文字を表示して、改行を出力。それを繰り返す場合は次の通り。
$ hexdump -e '16/ "%_p "' -e '"\n"' a.txt A B C D E F G H I J K L M N O P Q R S T U V W X Y Z .
バイトカウント 16 でオフセットを出力して、同時に改行も出力する場合は次の通り。
$ hexdump -e '/16 "%08_ax\n"' a.txt 00000000 00000010
以上、ここではヘックスダンプを行う hexdump コマンドの使い方を説明しました。